" alt="">
" alt="">На ранньому етапі компанії Nutanix одним із головним профілів використання системи була віртуалізація робочих місць. Проте з ростом популярності все більше замовників мігрували більш вимогливі до продуктивності задачі/навантаження (напр. бази даних) на платформу Nutanix. Але яка ситуація з високонавантаженими базами даних, які до сих пір тримають на виділених системах зберігання даних?
Нижче наведений слайд, що був презентуваний у 2017 році на щорічній конференції Nutanix Next. Сюди ж доданий до порівняння графік з показниками продуктивності платформи Nutanix в конфігурації NVMe + SSD з програмним забезпеченням Nutanix AOS 6.0. Слайд відображає порівняння результатів тесту продуктивності, де можна побачити фактично двократний ріст продуктивності дискової підсистеми. Якщо ви ще кілька років тому сумнівались у доцільності використання гіперконвергентних систем для важких задач, то тепер можете переконатись на власному досвіді, що система повністю задовольнить будь-які вимоги.
Давайте глянемо на іншу систему у тестовому середовищі. Вона використовує STS версію AOS, а конфігурації дискової підсистеми – це кілька накопичувачів Intel Optane та мережеві адаптери з підтримкою технології RDMA (віддалений прямий доступ до пам’яті) на сервер. Нижче наведено результати стандартного тесту на продуктивності для цієї системи, що складається з 4ох серверів.
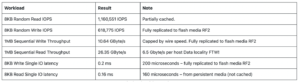
Варто звернути увагу не на великий показник дискових операцій та пропускну здатність, а на досить низькі показники затримки доступу до даних для кожної одиниці дискової операції. Особливо помітна затримка на операції запису в 200 мікросекунд, і це всього лиш з двох дисків на двох різних серверах кластеру. А показник затримки для операцій читання дорівнює 160 мікросекунд, що вказує на те що операції читання обслуговуються дисками, а не кешем в оперативній пам’яті CVM.
А тепер до найцікавішого – тести продуктивності баз даних
Результати вище отримані шляхом використанням продукту X-Ray для тестування систем у різноманітних сценаріях, включаючи відмову серверів чи цілої системи. Його задача вижимати з системи максимум і відповідно ці тести далекі від реальних сценарії навантаження.
Зазвичай інженерів замовників більше цікавлять показники операцій вводу/виводу, які транслює система управління базами даних. Майже завжди навантаження баз даних – це мікс операцій вводу та виводу різного розміру, з різною довжиною черги та типу операцій (читання та запису) з більшою робочою кількістю даних ніж в тестах вище. Але як правило це твердження вірне і для тестів інших виробників систем зберігання даних.
Давайте глянемо на результати двох тестів з різними сценаріями:
- Один єдиний інстанс Microsoft SQL Server (на одному серверному кластері) з запущеним тестом HammerDB TPC-C;
- Набір баз даних Oracle з запущеним SLOB на 4 серверах кластеру Nutanix.

Давайте разом розглянемо, як Nutanix досяг таких результатів та проаналізуємо їх більш глибоко.
Частина I. Оптимізації
Крок №1 – Збільшення продуктивності на великих робочих наборах даних
Кілька років тому у Nutanix переглянули свою архітектуру метаданих і внесли ряд змін, напрямлених на збільшення продуктивності. Був доданий новий механізм локального зберігання метаданих RockDB, що має відношення до навантаження запущеного на кожному конкретному сервері кластеру, але також глобально використовує розподілену систему зберігання метаданих кластера Cassandra. Більш детально про це можна почитати за посиланням в розділі Scalable Metadata.
Ці нововведення кардинально вирішили питання затримки доступу до метаданих при оперуванні великими наборами даних, що фактично відображає реальне навантаження високонавантажених баз даних. Фактично отримали х2 збільшення продуктивності для двох основних задач:
- Великий робочий набір даних для операцій читання з випадкових профілей (Random);
- Завантаження в БД великого об’єму даних та відновлення з бекапу.
Нижче на малюнку наведені результати внутрішніх тестів Nutanix з включеним та виключеним нововведенням, яке тепер називається Autonomous Extent Store (AES).


Крок №2 – Покращення затримки запису в лог баз даних
Для багатьох систем управління баз даних операції для журналу транзакцій відбуваються в один потік. При однопоточному робочому навантаженні єдиний спосіб оптимізації — зменшити затримку. Архітектура гіперконвергентних систем кардинально відрізняється від традиційних систем зберігання даних, де два контролери об’єднані між собою високопродуктивною шиною та кожен оснащений NVRAM пам’яттю, де відбуваються всі операції запису. Відповідно це є потенційним мінусом архітектури гіперконвергентних систем, що напряму впливає на затримки операцій запису для баз даних.
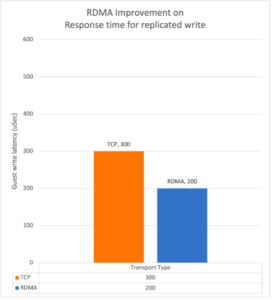
Проте використання технології віддаленого прямого доступу до пам’яті (RDMA) в поєднанні з NVMe дисками дозволяє кардинально зменшити затримку для операцій запису. З сучасним обладнанням одна операція запису в БД потрапляє на NAND пам’ять накопичувачів на різних серверах (копія для відмовостійкості) кластера із затримкою приблизно в 200 uSec. Це в свою чергу значно збільшує продуктивність для навантаження з вимогою низьких затримок та навіть реалізації сценаріїв БД в оперативній пам’яті. Додамо, що Nutanix були першими в сертифікації гіперконвергентної системи для SAP HANA та пройшли її з першого разу.
Крок №3 – покращення ефективності вцілому, зменшення затримок доступу та навантаження на центральний процесор.
Після всіх вдосконалень, описаних вище, Nutanix сфокусувались на низько-рівневих оптимізаціях операційної системи та її ядра.
В 2020 компанія Nutanix представила технологію Blockstore та SPDK, що дозволяє не використовувати системні виклики для роботи з NVMe накопичувачами, уникаючи переключення контексту на рівень ядра ОС, а виконувати всі операції на рівні користувача. Це не тільки покращує продуктивність, але й збільшує ефективність.
Тести показують ріст продуктивності на 10-20% для баз даних.
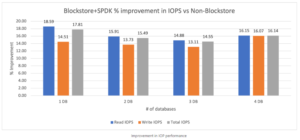
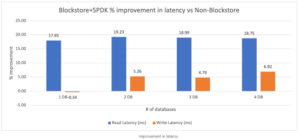
Крок №4 – Lift & Shift міграція
Останні покращення дозволяють отримати миттєвий ріст продуктивності після міграції без застосувань кращих практик до конфігурації віртуальної машини на платформі Nutanix та конкретної системи управління бази даних. Багато замовників задумуються над міграцією в публічні хмари або ж на “нове покоління” систем зберігання даних, а це може вимагати від інженерів рефакторингу програмного забезпечення, зміни конфігурації і т. д., щоб отримати той же рівень продуктивності.
Nutanix використовує вбудований механізм дроблення (sharding) дисків для отримання паралельних операцій на рівні підсистеми зберігання даних, а що найголовніше – це все без будь-якого втручання адміністратора в зміну конфігурації БД та віртуальної машини.
Nutanix покращили продуктивність для одного диску, на якому зберігається база даних фактично в 2 рази без необхідності оптимізації БД з розбиттям її на кілька файлів і дисків.
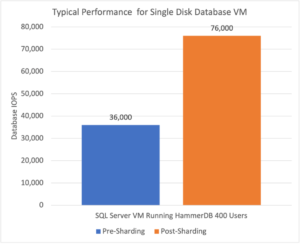
Частина II. Результати
Враховуючи всі вище описані вдосконалення, чи було досягнуто переламного моменту для міграції більшості сценаріїв навантаження баз даних на гіперконвергентну систему Nutanix?
Microsoft SQL Server
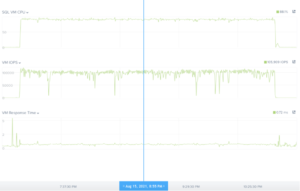
Друга за популярністю система управління баз даних на Nutanix – це Microsoft SQL Server, тестове навантаження згенероване HammerDB (TPC-C). Ми бачимо затримку менше 1 ms на рівні ОС віртуальної машини. Підсистема зберігання даних генерує рівномірне навантаження на 16 ядер процесора віртуальної машини з фактично 100% утилізацією обчислювальних ресурсів.
Продуктивність консистентна протягом кількох годин виконання тесту
PostgreSQL
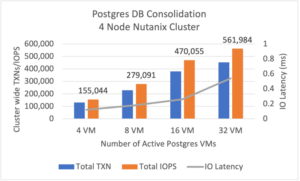
Далі дослідили, які результати буде отримано при роботі великої кількості віртуальних машин з базами даних PostgreSQL. Отже на 4 серверах кластеру запустили 32 віртуальні машини з PostgreSQL та отримали 500000 операцій з затримкою менше 1 ms.
Oracle
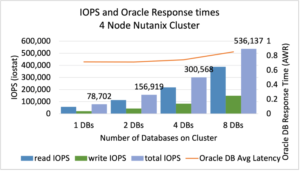
І нарешті Oracle – запущено SLOB тест. Підсистема зберігання даних показала більше 500000 дискових операцій із затримкою менше 1 ms.
Висновок
За останні кілька років Nutanix пройшли довгий шлях. Приблизно з 2018 року працюють над покращенням продуктивності бази даних на HCI. І все ще на цьому шляху, але тепер стало можливим успішно виконувати завдання, які були б неможливими ще 2-3 роки тому.
За матеріалами Nutanix